递归:Recursion
递归实际是通过函数体来进行的一种循环:
从前有座山
山里有座庙
庙里有个和尚讲故事:
从前有座山
……
例一:求n的阶乘n!:
n!=1*2*3*……*n
def Factorial(n):
if n= 1:
return 1
return n * Factorial(n-1)
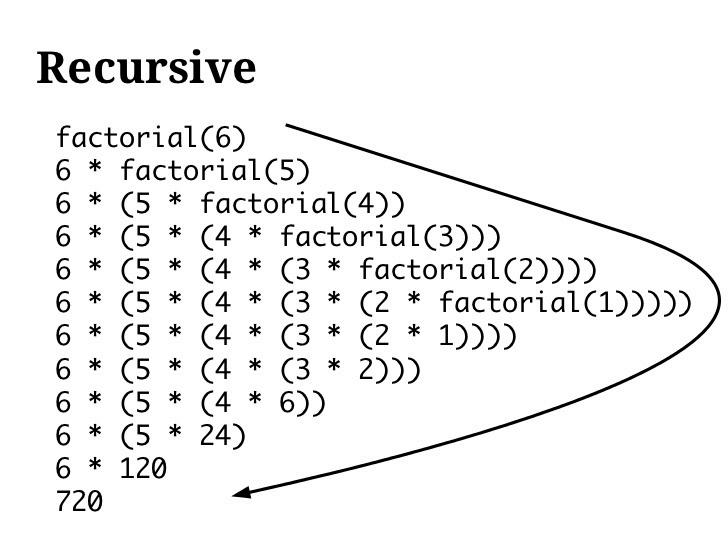
递归求阶乘
例二:求斐波那契数列第n项
F(n)=F(n-1)+F(n-2)
def fib(n):
if n==0 or n==1:
return n
return fib(n-1)+ fib(n-2)
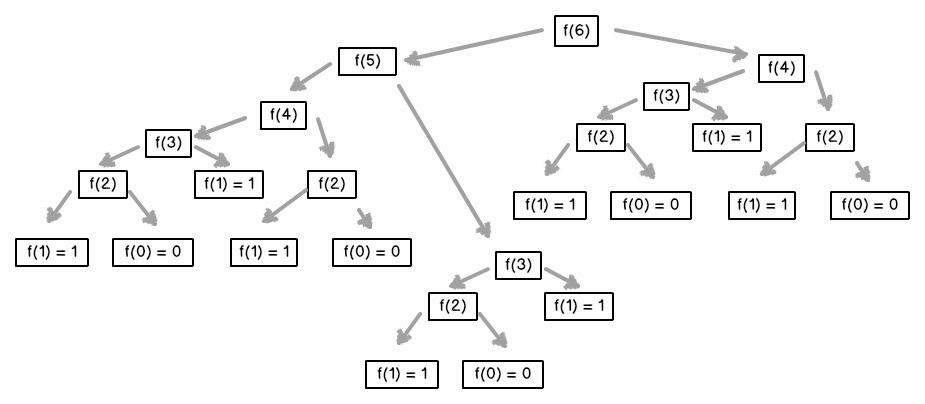
递归求解斐波那契第六项
- 定义终止条件
- 当前层问题数据操作
- 递归求解下一层结果
- 汇总计算结果得到问题解
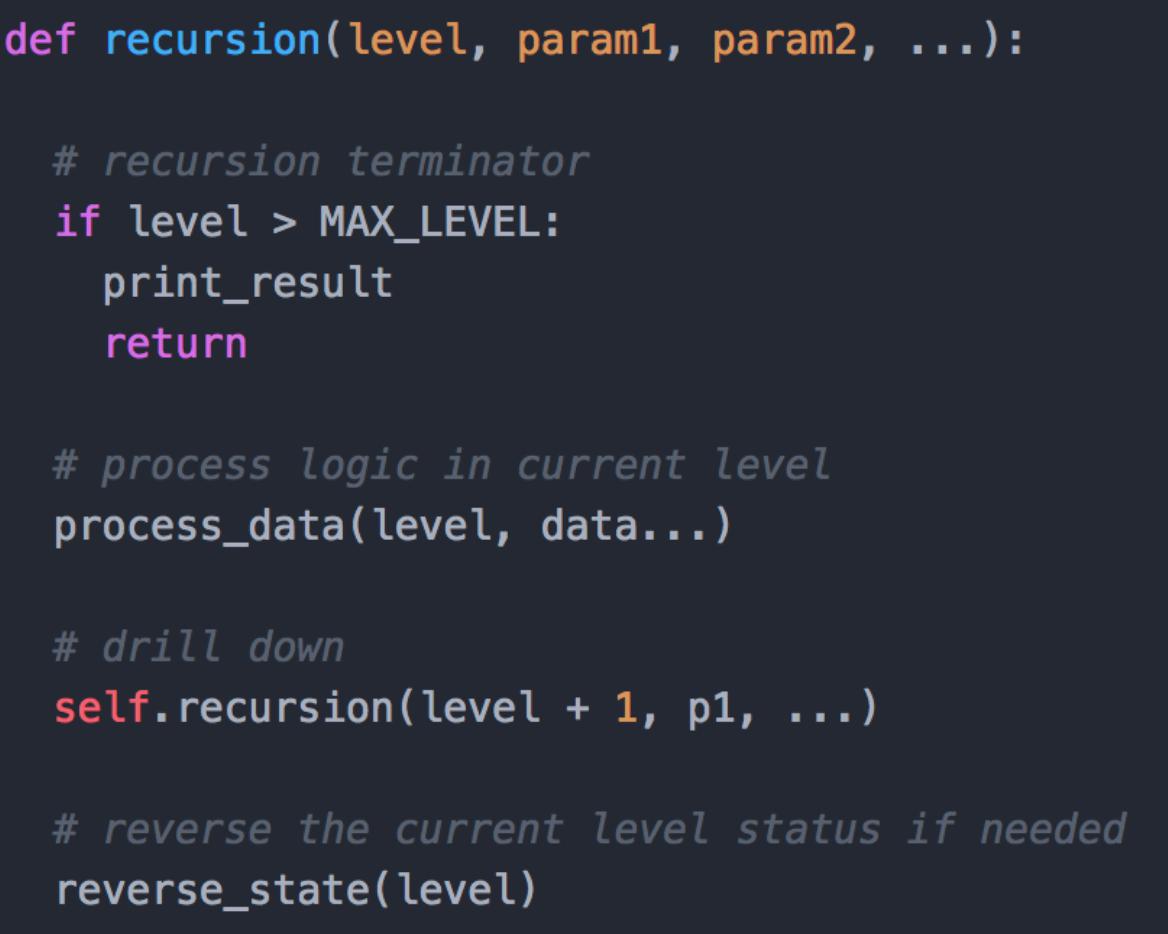
递归程序的模板
分治:Divide & Conquer
先把问题Chunk it up切成小块,然后并行解决这些小问题
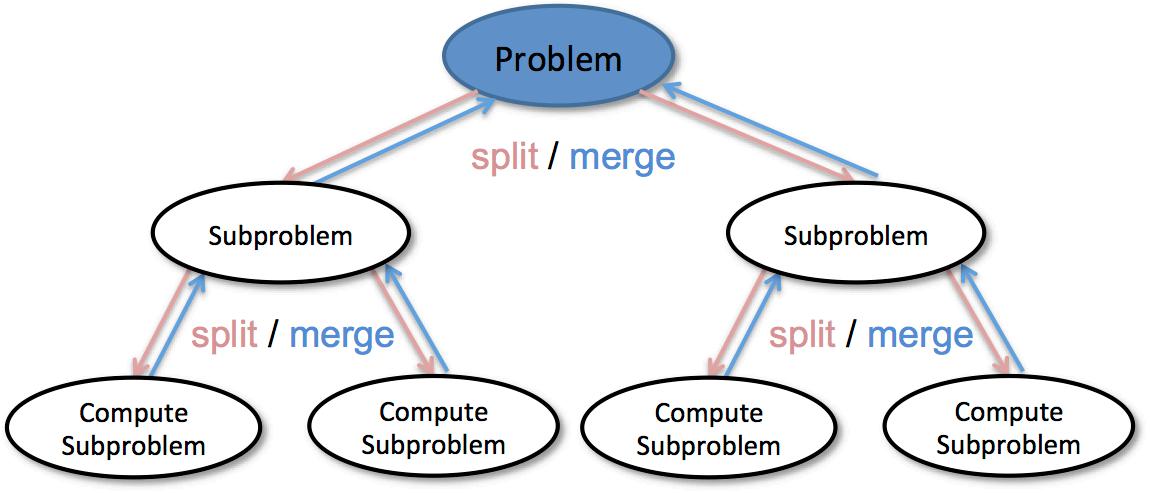
分治示意图
例:将字符串中小写字母全部替换成大写字母
思路:将字符串不断划分,最后以单个字符为单位进行替换,这样每个子问题之间互无依赖关系,最重要的是可以并行计算
 分治替换小写字母
分治替换小写字母
分治能解决问题的条件是子问题相互独立,问题求解没有中间结果和重复计算,否则性能会急速退化 如果子问题存在中间结果或重复计算问题,可以使用动态规划或记忆优化(求解过程中保存每步计算结果)
一般而言,分治是通过递归解决的,所以代码实现上和递归也有相似之处:
- 定义终止条件
- 当前层问题数据操作
- 拆分子问题
- 分别求解子问题
- 汇总计算结果得到问题解
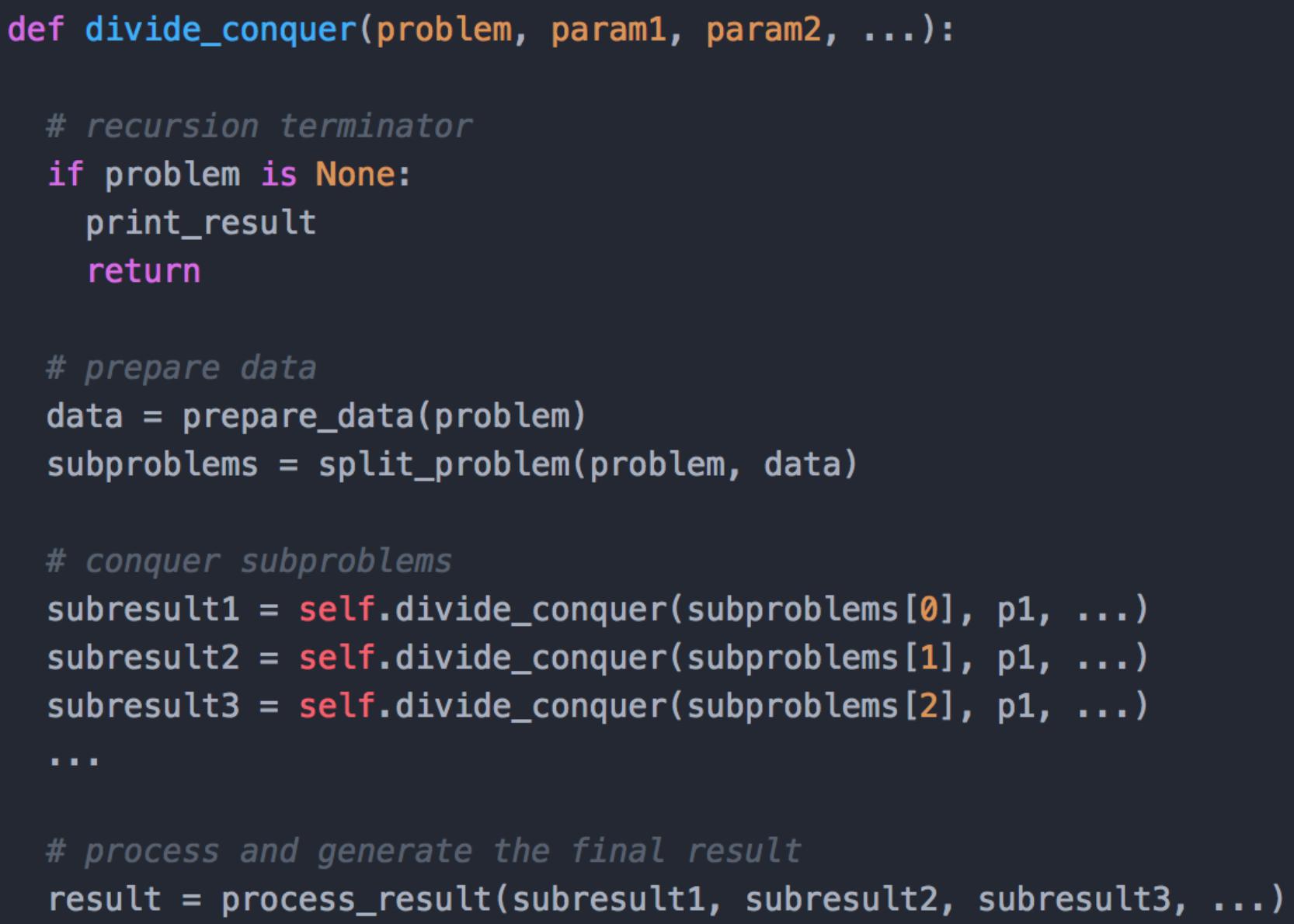
分治代码模板
实战题目
求Pow(x,n) Pow(x,n)即为xn,
- 思路一:直接调用库函数,不推荐
- 思路二:暴力求解,n次乘法循环,不推荐
- 思路三:分治思想,递归实现:Pow(x,n)=xn/2*xn/2(n为偶数)或Pow(x,n)=x(n-1)/2*x*x(n-1)/2,时间复杂度O(logN)
def myPow( self, x, n): if not n: return 1if n< 0: return 1 / self.myPow(x,-n) if n % 2: return x * self.myPow(x,n-1) return self.myPow(x*x,n/2) - 不使用递归:
def myPow(self, x, n): if n < 0: X = 1/× n = -n pow = 1 while n: if n & 1: pow *= x x *= x n >>= 1//使用位运算,移一位相当于乘以n return pow
求多数元素 所谓多数元素,指出现次数>len/2,其中len为数组长度
- 思路一:暴力求解,循环遍历每个元素,每个元素再循环遍历计数,时间复杂度O(N2)。
- 思路二:使用map{x:count_x},遍历每个元素且count+1,最后返回map中value最大元素即可,时间复杂度、空间复杂度均为O(N)
- 思路三:先将数组排序,然后遍历元素并计数,当count达到n/2即返回结果,时间复杂度O(NlogN)
var majorityElement = function(nums) { if(nums.length==1) return nums[0] nums.sort((a,b)=>{ return a-b }) console.log(nums) let pre=0,cur,count=0,len=nums.length for(let index in nums){ if(index==0){ index++ } cur=nums[index]; pre=nums[index-1] if(pre==cur){ if(++count>len/2){ return cur } } else if(pre!=cur){ count=1 } } }; - 思路四:分治求解,数组左半元素的majority与右半元素majority中求最大值,即 return left>=right?left:right
class Solution { int count_in_range(vector<int>& nums, int target, int lo, int hi) { int count = 0; for (int i = lo; i <= hi; ++i) if (nums[i] == target) ++count; return count; } int majority_element_rec(vector<int>& nums, int lo, int hi) { if (lo == hi) return nums[lo]; int mid = (lo + hi) / 2; int left_majority = majority_element_rec(nums, lo, mid); int right_majority = majority_element_rec(nums, mid + 1, hi); if (count_in_range(nums, left_majority, lo, hi) > (hi - lo + 1) / 2) return left_majority; if (count_in_range(nums, right_majority, lo, hi) > (hi - lo + 1) / 2) return right_majority; return -1; } public: int majorityElement(vector<int>& nums) { return majority_element_rec(nums, 0, nums.size() - 1); } };
-
int maxSubArray(int* nums, int numsSize){ int result = INT_MIN; int sum = 0; for (int i = 0; i < numsSize; i++) { sum += nums[i]; result = max(result, sum); //如果出现负值,直接抛弃 if (sum < 0) sum=0 } return result; } int max(int a,int b){ return a>b? a:b; } - 有效字母异位词
思路一:对两个字符串按字符大小进行排序,再调用join('')方法拼接。如果两个字符串是异位词,则处理后的字符串必然是相同的的。该方法时间复杂度O(lgN),空间复杂度O(lgN)
var isAnagram = function(s, t) { return s.length == t.length && [...s].sort().join('') === [...t].sort().join('') };思路二:统计思想。如前求多数元素题,可以维护两个map,分别记录两个字符串中字符出现的次数。
var isAnagram = function(s, t) { if (s.length !== t.length) { return false; } const table = new Array(26).fill(0); for (let i = 0; i < s.length; ++i) { table[s.codePointAt(i) - 'a'.codePointAt(0)]++; } for (let i = 0; i < t.length; ++i) { table[t.codePointAt(i) - 'a'.codePointAt(0)]--; if (table[t.codePointAt(i) - 'a'.codePointAt(0)] < 0) { return false; } } return true; };- 思路一:遍历主串中长度等于模式串的子串,分别调用上一题的IsValidAnagram方法,如果结果为true就把下标记录下来,最后返回下标数组即可。
- 思路二:在上一题基础上,采取“滑动窗口”的思想,在主串中不停地滑动固定长度的窗口,维护(而不是从头开始)窗口内各字符的数量并与模式串进行匹配。
思路三:在滑动窗口的基础上进行优化改进。不再分别统计滑动窗口和模式串中每种字母的数量,而是统计滑动窗口和模式串中每种字母数量的差;并引入变量 differ 来记录当前窗口与模式串中数量不同的字母的个数。并在滑动窗口的过程中只需判断differ是否为0即可
var findAnagrams = function(s, p) { const sLen = s.length, pLen = p.length; if (sLen < pLen) { return []; } const ans = []; const count = Array(26).fill(0); for (let i = 0; i < pLen; ++i) { ++count[s[i].charCodeAt() - 'a'.charCodeAt()]; --count[p[i].charCodeAt() - 'a'.charCodeAt()]; } let differ = 0; for (let j = 0; j < 26; ++j) { if (count[j] !== 0) { ++differ; } } if (differ === 0) { ans.push(0); } for (let i = 0; i < sLen - pLen; ++i) { if (count[s[i].charCodeAt() - 'a'.charCodeAt()] === 1) { // 窗口中字母 s[i] 的数量与字符串 p 中的数量从不同变得相同 --differ; } else if (count[s[i].charCodeAt() - 'a'.charCodeAt()] === 0) { // 窗口中字母 s[i] 的数量与字符串 p 中的数量从相同变得不同 ++differ; } --count[s[i].charCodeAt() - 'a'.charCodeAt()]; if (count[s[i + pLen].charCodeAt() - 'a'.charCodeAt()] === -1) { // 窗口中字母 s[i+pLen] 的数量与字符串 p 中的数量从不同变得相同 --differ; } else if (count[s[i + pLen].charCodeAt() - 'a'.charCodeAt()] === 0) { // 窗口中字母 s[i+pLen] 的数量与字符串 p 中的数量从相同变得不同 ++differ; } ++count[s[i + pLen].charCodeAt() - 'a'.charCodeAt()]; if (differ === 0) { ans.push(i + 1); } } return ans; };
回溯
回溯更多地是一种思想,往往通过递归或迭代实现。
贪心
贪心法,又称贪心算法、贪婪算法:
在对问题求解时,总是做出在当前看来是最好的选择
举例:张数最少的零钱

贪心法解决换零钱问题
贪心算法得到的结果并不一定是最优解:比如上面换零钱的例子,加入总金额18,只有面额10、9、1的纸币,最优解是2张,贪心法得到的结果却是9张
贪心法适用场景
简单地说,问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。这种子问题最优解叫做最优子结构。
贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能。
实战题目
- 买卖股票的最佳时机
问题描述:任何时刻最多持有1股,每天可买卖无数次,输入是表示一支股票每天价格的数组,输出是可能的最大收益
- 思路一:对每一天的买/卖作深度优先搜索,时间复杂度O(N2)
- 贪心算法,只要后一天的价格比前一天高,则在前一天买入。若已买入,后一天价格比前一天价格低则在前一天卖出。
使用一层循环,两个变量分别表示前面的价格和后面的价格。时间复杂度O(N),空间复杂度O(1) - 思路二:动态规划解法,把每一天的状态(买入/卖出)记录下来,保存最大利益,每一天和前面一天比较,判断是买入还是卖出
int maxProfit(int* prices, int pricesSize){ if(pricesSize==0)return 0; int left=0,right=1,sum=0; while(right< pricesSize){ int dif = prices[right]-prices[ left]; if(dif>0)sum+=dif; left++;right++; } return sum; }
-
- 思路:贪心法解决,对每一笔收款进行遍历,判断其大小进行选择。如果需要找零,优先找给面额大的,再考虑面额小的。如果前面某一步已经不能找零了,后面就不用考虑了。
var lemonadeChange = function(bills) { let arr=[0,0,0]//用三个变量记录,时间更快 console.log(arr) for(let bill of bills){ console.log(bill) switch(bill){ case 5: arr[0]++; break; case 10: if(arr[0]>=1){ arr[0]--; arr[1]++; break; } else return false; case 20: if(arr[0]>=1){ if(arr[1]>=1){ arr[0]--; arr[1]--; arr[2]++; break; } else if(arr[0]>=3){ arr[0]-=3; arr[20]++; break; } else return false; } else return false; } } return true; };
- 思路:贪心法解决,对每一笔收款进行遍历,判断其大小进行选择。如果需要找零,优先找给面额大的,再考虑面额小的。如果前面某一步已经不能找零了,后面就不用考虑了。
-
思路:贪心法解决,优先满足小食量的小朋友,并优先分配小饼干
var findContentChildren = function(g, s) { let child=0,cookie=0 g.sort((a,b)=>a-b); s.sort((a,b)=>a-b); while(child<g.length&& cookie<s.length){ if(g[child]<=s[cookie]){ child++; } cookie++; } return child; };
-
思路:对机器人的每一条指令,进行一步一步的模拟。使用dx、dy两个一维数组进行前进方向的确定,使用set\
class Solution { public: int robotSim(vector<int>& commands, vector<vector<int>>& obstacles) { int dx[4] = {0, 1, 0, -1};//方向数组,x=1表示东,x=-1表示西 int dy[4] = {1, 0, -1, 0};//y=1表示北,y=-1表示南 int x = 0, y = 0, di = 0; set<pair<int, int>> obstacleSet; for (vector<int> obstacle: obstacles) obstacleSet.insert(make_pair(obstacle[0], obstacle[1]));//障碍物以pair形式提前存储在set里面,便于快速查找。这里注意障碍物的二维坐标是多对多关系,简单的K-V对不能存储 int ans = 0; for (int cmd: commands) {//转向或前进操作 if (cmd == -2) di = (di + 3) % 4; else if (cmd == -1) di = (di + 1) % 4; else { for (int k = 0; k < cmd; ++k) { int nx = x + dx[di]; int ny = y + dy[di]; if (obstacleSet.find(make_pair(nx, ny)) == obstacleSet.end()) { x = nx; y = ny; ans = max(ans, x*x + y*y);//维护欧氏距离 } } } } return ans; } };